Empeg File Structures
If you’ve ever gone looking for the music and playlists on your empeg, you’ll find them in the /empeg/fids0 and /empeg/fids1 directories.
Instead of the descriptive filenames you might have been expecting, the files are all named with cryptic numbers.
FIDs
Each of these cryptic numbers is referred to as a FID, which is short for File ID. FIDs are 32-bit numbers, where the low 4 bits have a special meaning. Since FIDs are usually written out in hex, this means that these are represented in the last character of the filename.
For example, a given track might end up being assigned FID 1c0. There will be a file called 1c0 containing the audio data for the file, in MP3 or Ogg Vorbis or whatever. Along with this file is another one, named 1c1, which contains the tag information for this file.
Another track might be assigned FID 2e0 and, again, there’ll be a pair of files: one named 2e0, containing the audio data, and another named 2e1, containing the tag information for that track.
FID Suffixes
| **Suffix** | **Description** |
| *0 | The audio data for the file. |
| *1 | The tags for the file. |
| *2 | On Rio Central, the low-bitrate audio data, for downloading to portables. This is not used on the car player. |
| *3-*E | Reserved. |
| *F | You'll sometimes see files with this suffix. This is a bug in emplode/JEmplode. The *F number is used to refer to a FID's dynamic data, and should have been written to the dynamic data partition, rather than to the music partition. |
FID Allocation
When choosing a FID for a new playlist or track, emplode just picks the next highest unused FID. Because the low 4 bits are reserved, each FID is 16 (0x10) higher than the previous one.
FID 0x100 is reserved for the root playlist. FID 0x110 is reserved for the (historical) “Unattached Items” playlist. FIDs less than 0x100 are reserved. Some of them are used as special numbers in the upload protocol. Some of them are used internally by emplode.
These are listed in the lib/protocol/fids.h in the emptool source code. If I get round to documenting the protocol properly, I’ll cover the first group in more detail.
Thus, FID 0x120 is the number assigned to the first normal playlist or track on your player.
Space Allocation
These two directories, /empeg/fids0 and /empeg/fids1 are actually symlinks to /drive0/fids and /drive1/fids, respectively. This means that each one refers to a different disk in a two-drive empeg.
If you’ve only got a single-drive empeg, the second /drive1/fids directory isn’t used (this is fairly obvious – it refers to a disk that isn’t there).
When choosing which drive to put a particular FID on, the empeg simply looks for the one that has the most space free. This means that if you have two disks of roughly the same size, the files will tend to alternate between the two drives. If you’ve got two disks of different sizes, the larger disk will tend to fill up first.
FID Subdirectories
When the player was still at version 1.0, the FID files were all in the same directory (except when they were on separate disks, of course). As the number of files in a directory increases, the performance worsens.
At some point in the v2.0 beta releases, the player began supporting a slightly different layout for these two directories. In order to improve performance, the files can now be put into subdirectories.
This is done by extending the FID number to 8 hex digits by prefixing with zeros. Then we split this into 5:3, taking the first 5 digits as a directory name (which starts with an underscore). The remaining 3 digits are the name of the file within that directory.
So, for example, FID 186f0 would be found in the file _00018/6f0 (with its tags in _00018/6f1).
This new layout is supported by the v2.0 players when looking for files, but when writing them, it uses the old, v1.0-compatible layout.
In v3.0, it writes the files to the new layout, but supports the old layout, to ensure that it works on players still using the old layout.
Tags (*1 Files)
As mentioned, each FID usually has two files, the *0 file and the *1 file. The *0 file contains the audio (or playlist data), and the *1 file contains the tag information for that file.
Each *1 file is a plain Unix-style text file: line endings are a single LF (0x0a) character. Each line of the file is of the form tag=value. For example, one of the tag files on my player looks like this:
artist=U2 bitrate=vs205 codec=mp3 ctime=1048268091 duration=228043 file_id=3 length=5871620 offset=97 samplerate=44100 source=All That You Can't Leave Behind title=Elevation tracknr=3 type=tune
In this particular example, all of my tags are in alphabetical order. This is an artifact of the way that emplode deals with tags internally. The tags can be in any particular order.
Common Tag Names
The *1 files can contain any tags you like. Bear in mind that when the player builds the database file, all of these tags end up in there. Because the database file takes up memory, you’d be advised to put in the *1 file only information that’s needed.
| **Tag Name** | **Description** |
| artist | The artist for the track, e.g. "U2". |
| bitrate | See "bitrate", below. |
| codec | See "codec", below. |
| ctime | The time when the track or playlist was put on the player. It's short for "creation time". It's a Unix-style time_t value, counting the number of seconds since Jan 1st, 1970. Other information, like the last time the track was played goes into the dynamic data partition. |
| duration | The length of the track, in milliseconds. |
| file_id | Normally this is the same as the "tracknr" tag. On the Rio Central, it refers to the original track number of a particular track. It's used in the CD ripping code. |
| genre | The genre of the track, e.g. "Rock". |
| length | The length of the track, in bytes. For tunes, this is used as a hint to the caching code. For playlists, it's more important. See "Playlist FID files", below, for more information. |
| offset | How much non-audio data to skip at the start of the file. Generally this is the length of the tag information or album art. |
| options | See "options", below. |
| pickn | See "pickn", below. |
| pickpercent | See "pickpercent", below. |
| samplerate | The sample rate, in Hz. For MP3 data, this is usually 44100, or 44.1kHz. |
| source | The album name of this track. It's not called "album", because a lot of Mike's tracks are from the radio, and "BBC Radio 4" isn't an album name. |
| title | The name of this track. |
| tracknr | The track number of this track. |
| type | Whether this file is a playlist or a tune. |
| year | The year of this track. |
Other Tag Names
You occasionally see these tag names, but they’re less common:
| **Tag Name** | **Description** |
| comment | Any comments you want to associate with the track. |
| fid_generation | See "fid_generation", below. |
| trailer | The same as "offset", but for the end of the file. |
| rid | A relatively unique ID for the file. See "rid", below. |
bitrate
This is a hint to the caching code and decoder. It must consist of two letters followed by a number.
| **First Letter** | **Meaning** |
| f | Fixed Bitrate |
| v | Variable Bitrate |
| ? | Unknown |
| **Second Letter** | **Meaning** |
| m | Mono |
| s | Stereo |
| ? | Unknown |
The number is the bitrate in Kbps. My example file above (Elevation by U2) is a variable bitrate, stereo file, at around 205Kbps.
Quite often you’ll see “fs128”, which means fixed-rate, stereo, 128Kbps. This is a sensible default value if you don’t want to work out the bitrate.
codec
Which codec will be used to play the file?
| **codec Value** | **Description** |
| mp3 | Use the MP3 decoder |
| wave | Use the WAV (PCM) decoder |
There are other values for Ogg Vorbis, FLAC and Windows Media, but I don’t remember what they are.
fid_generation
This is an artifact from Rio Karma support in JEmplode.
On the empeg, a playlist is just a list of the FIDs contained in that playlist. This means that when you delete a FID, you have to find every playlist containing that FID and remove the deleted FID. This is needed because FIDs can be reused.
On the Rio Karma, on the other hand, a playlist is a list of pairs: (FID, generation). When a FID is replaced, its generation number is guaranteed to be higher than any number used in the past.
When loading a playlist, Karma can compare the generation number in the playlist with the generation number in the FID. If they’re different, it knows that the FID has been reused, and that it shouldn’t include this FID in the loaded playlist. This avoids having to rewrite every playlist when you delete a FID from the player.
The only requirement for this number is that it be different from any other generation number previously assigned to this FID. Rather than keeping a list of all the previous numbers ever used for any FID, there are two possible optimisations: use a single incrementing number for all of the content on the player; or use a timestamp.
JEmplode uses a timestamp, which is why this is usually the same as the ctime value.
options
This is a hex number, usually prefixed with 0x. Earlier versions of emplode didn’t include the 0x prefix. It’s a bitmask of the various options attached to this track or playlist.
Documentation for these numbers can be found in the emptool source code, in the lib/protocol/fids.h file. They are:
| **Name** | **Value** | **Applies To** | **Description** |
| PLAYLIST_OPTION_RANDOMISE | 0x00000008 | Playlists | When this playlist is included, should the player always randomise the content. This is different from the various shuffle modes that the player supports. This value is from the "Always randomize contents" checkbox in emplode. |
| PLAYLIST_OPTION_LOOP | 0x00000010 | Playlists | When reaching the end of the playlist, should the player immediately start again. This is only used if you're playing this playlist, rather than a parent of this playlist. From the "Automatically repeat" checkbox in emplode. |
| PLAYLIST_OPTION_IGNOREASCHILD | 0x00000020 | Playlists | From the "Ignore as child" checkbox in emplode. See the [riocar.org FAQ](http://www.riocar.org/modules.php?op=modload&name=FAQ&file=index&myfaq=yes&id_cat=4&faqent=31#31) for details of what this does. Personally, I use it to ensure that Harry Potter doesn't appear in the playlist when I use down-down-down. |
| PLAYLIST_OPTION_CDINFO_RESOLVED | 0x00000040 | Tracks | On Rio Central. Have we looked up this track in CDDB yet? |
| PLAYLIST_OPTION_COPYRIGHT | 0x00000080 | Tracks | On Rio Central, used for Serial Copying Management System (SCMS) support. See [this page](http://www.xs4all.nl/~jacg/dcc-faq/scms.html), for example. |
| PLAYLIST_OPTION_COPY | 0x00000100 | Tracks | On Rio Central, used for SCMS support. |
| PLAYLIST_OPTION_STEREO_BLEED | 0x00000200 | Tracks | Whether the player should mix up the left and right tracks a little when playing the track. Useful when you're listening to The Beatles with headphones, for example. |
pickn
When building a running order, rather than include the whole of this playlist, the player will pick a certain number of tracks from this playlist. It chooses them randomly.
pickpercent
Like pickn, above, but the player chooses a certain percentage of the tracks, rather than a certain number of them.
rid
This is another artifact from Rio Karma support in JEmplode. It’s used for ensuring that duplicate tracks are avoided.
When you load a track onto the player, emplode scans the database looking for tracks with the same tags. This doesn’t work particularly well if you’ve edited the tags since you last loaded the track.
To avoid this problem, Rio Music Manager introduces the concept of a unique ID which can be calculated from the audio data. It takes the MD5 checksum of three 64Kb chunks of the file: one from the beginning, one from the middle of the file and one from the end of the file.
JEmplode uses the same technique on the car player.
Oh, and the R stands for Roger. Cheers.
What about ID3 tags?
Once a file is put onto the player, the player will not pay any attention to the ID3 (or Vorbis comment) information in that file. It relies solely on the information in the *1 file while rebuilding its cached database.
Playlist FID files
Playlists are stored in a similar way to tracks. They have a pair of files: the *0 file for the playlist data, and the *1 file for the tag information.
For a playlist, the only required tags are type, title and length. Playlists don’t tend to have any other tags, because they’re not displayed anywhere in the player software and they’d be uselessly taking up space in RAM.
The *0 file is a list of the child FIDs, stored as little-endian 32-bit numbers. So, for example my “Remixes 81-04 - Disc 2” playlist (by Depeche Mode) has the following in its *0 file:
| **Offset** | **Bytes** | |||
| 0000000 | 30 02 00 00 | 40 02 00 00 | 50 02 00 00 | 60 02 00 00 |
| 0000020 | 70 02 00 00 | 80 02 00 00 | 90 02 00 00 | a0 02 00 00 |
| 0000040 | b0 02 00 00 | c0 02 00 00 | d0 02 00 00 | e0 02 00 00 |
This means that it contains FIDs 0x230, 0x240, 0x250, …, 0x2e0 as immediate children. Playlists can contain a mixture of playlists and tracks.
The length tag in the *1 file is in bytes. In this example, the playlist has 12 children (tracks), so the *1 file contains the line length=48.
Cached database
Rather than read all of the *1 files into memory when starting up (which would take a long time), the player builds a cached copy of all of that information.
It lives in three files in the /empeg/var directory:
| **File** | **Description** |
| database | A cached copy of the information from each *1 file. On v3-alpha players, it's called `database3`, and supports UTF8 tags. The format is the same as the `database` file. See "database", below. |
| playlists | A cached copy of the data from each of the playlist *0 files. See "playlists" below. |
| tags | See "tags", below. |
tags
This file is a simple text file, Unix format, LF (0x0a) line endings, with one tag per line. It’s built by scanning all of the *1 files and collecting the tag names. Mine looks like this:
type length title options pickn pickpercent ctime artist bitrate codec duration file_id genre offset samplerate source tracknr
The line reading “type” must occur first in this file, but the order of the remaining entries is not important.
database
This is a binary file. It’s built from the tag information for all of the tracks and playlists on the player. Tags are stored in the file as follows:
| **Offset** | **Size** | **Description** |
| 00 | 1 byte | Tag Number. This refers to the line number in the `tags` file, starting at zero. 0xFF is reserved. |
| 01 | 1 byte | Tag Length. Tags are stored as "Pascal style" strings. This is the length. Because it's a single byte, strings have a maximum length of 255 characters. |
| 02 | _tag-length_ bytes | The string data. It doesn't include a null terminator byte. |
So, for example, if I have a track where the artist is “Depeche Mode”, the tag will appear in the database file as follows:
| **Offset** | **Value** | **Description** |
| 00 | 0x07 | Tag Number. Refers to line 7 in the tags file. It's the artist. |
| 01 | 0x0C | Tag Length. This tag is 12 bytes long. |
| 02 | 0x44 0x65 0x70 0x65 0x63 0x68 0x65 0x20 0x4d 0x6f 0x64 0x65 | The string data, "Depeche Mode" |
Now, for each track, there’s a sequence of these, terminated by a 0xFF sentinel value. Here’s another example:
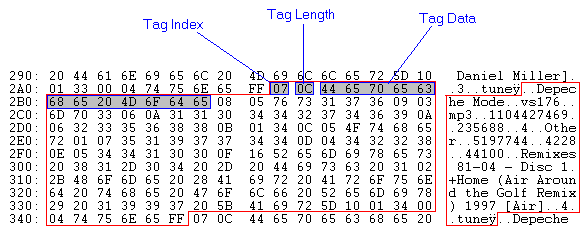
I’ve highlighted the same artist=Depeche Mode tag as above. You can see that it’s followed by tag 0x08 (bitrate), with length 0x05, containing “vs176”, and so on. The end of the record is marked with 0xFF. You can read the database record with some code like this:
while (1)
{
byte tagIndex = f.ReadByte();
if (tagIndex == 0xFF)
break;
byte tagLength = f.ReadByte();
byte[] tagData = f.ReadBytes(tagLength);
}
The file contains all of the tags for all of the FIDs, in FID order.
Unused FIDS (gaps) are marked with a single 0xFF byte in the database file.
Note: This means that you should avoid sparse FID numbering; you should attempt to keep the assigned FIDs as contiguous as possible. Each missing FID results in a wasted byte in the database file (and in RAM).
The database file includes dummy records for the first 16 reserved FIDs (0x00 to 0xF0). The first record (0x00 0x07 0x69 0x6c 0x6c 0x65 0x67 0x61 0x6c 0xFF) has a type (0x00) of “illegal” (0x7 bytes). The next 15 records are just the 0xFF terminator.
playlists
This file contains all of the playlists on the player. It’s a simple catenation of the *0 file for each playlist, in FID order.
It’s just a simple stream of little-endian 32-bit integers. It contains no record delimiters and no length prefixes.
You can get the length of each record from its corresponding length tag in the database file.
| **Offset** | **Bytes** | |||
| 0000000 | f0 02 00 00 | 10 01 00 00 | 20 01 00 00 | 30 01 00 00 |
| 0000020 | 40 01 00 00 | 50 01 00 00 | 20 02 00 00 | 60 01 00 00 |
| 0000040 | 70 01 00 00 | 80 01 00 00 | 90 01 00 00 | a0 01 00 00 |
| 0000060 | b0 01 00 00 | c0 01 00 00 | d0 01 00 00 | e0 01 00 00 |
| 0000100 | f0 01 00 00 | 00 02 00 00 | 10 02 00 00 | 30 02 00 00 |
| 0000120 | 40 02 00 00 | 50 02 00 00 | 60 02 00 00 | 70 02 00 00 |
| 0000140 | 80 02 00 00 | 90 02 00 00 | a0 02 00 00 | b0 02 00 00 |
| 0000160 | c0 02 00 00 | d0 02 00 00 | e0 02 00 00 | 00 03 00 00 |
| 0000200 | 10 03 00 00 | 20 03 00 00 | ||
You need the length information in order to make any sense of this. We’ll work through it. The first entry in the file is the root playlist, FID 0x100. By looking at the tags for this file, we know that it’s 12 bytes long. That gives us the first 3 entries, so we know that there are 3 entries in the root, with FIDs 0x2f0, 0x110 and 0x120.
The next playlist on the player is 0x120. Looking at the tags for it, we see that it’s 4 bytes long. That means it has one entry, with FID 0x130.
The next playlist is 0x130. It’s 4 bytes again, so it has one entry, FID 0x140.
0x140 is 8 bytes long. It contains FIDs 0x150, 0x220.
0x150 is 48 bytes long. It contains 12 entries: 0x160, 0x170, 0x180, 0x190, 0x1a0, 0x1b0, 0x1c0, 0x1d0, 0x1e0, 0x1f0, 0x200, 0x210. If you load everything in a playlist at the same time as you create the playlist, you’ll tend to see these increasing sequences in each playlist.
FIDs 0x160 to 0x210 are tunes. The next playlist is FID 0x220 which, again, is 48 bytes long, giving us entries 0x230, …, 0x2e0 from the playlists file.
The next playlist is 0x2f0. It’s 12 bytes long, which neatly uses up the last 3 entries: 0x300, 0x310, 0x320. When you break it all out, it leads to a playlist hierarchy like this:

See Also
Cliff L. Biffle’s documentation for the Karma’s network protocol is useful for considering some of this stuff. You can find it at http://www.cliff.biffle.org/software/pearl/