{error, closed}; nothing logged
I’ve just spent about a day poking around in the guts of Erlang/OTP and Ranch, and I thought I’d write some of it down.
Client gets {error, closed} when connecting; nothing logged
I needed to refresh my memory of how to use Ranch, so the first thing I did was start a ranch TLS listener and attempt to connect to it.
Something like this (except that I actually did it in Elixir, of which more later):
TransportOpts = #{socket_opts => [{port, 5555}, {certfile, "server.crt"}, {keyfile, "server.key"}]},
{ok, _} = ranch:start_listener(
example,
ranch_ssl, TransportOpts,
example_protocol, #{}).% In another REPL
{ok, Socket} = ssl:connect("localhost", 5555, []).…but it was simply failing with {error, closed}, and nothing was logged at the server.
tl;dr: Make sure that certfile and keyfile refer to valid, PEM-formatted certificate and key files.
If that spoiler is sufficient, great.
If not, follow me into the depths of ranch and Erlang. Oh, and some Wireshark.
I should also point out that I knew this was the problem; what was annoying me was why it was failing silently. We’re going to be deploying a service using this stuff. If it fails because of a configuration problem, I’d rather it failed noisily.
Wireshark
In order to check that the connection attempt was actually making it to the server, I captured a network trace with Wireshark and took a look at it.
Because it’s a pain to embed Wireshark in a blog post, here’s some (abbreviated) tshark instead:
$ tshark -i lo -f "port 5555"
Capturing on 'Loopback: lo'
1 0.000000000 127.0.0.1 → 127.0.0.1 TCP 74 55513 → 5555 [SYN] Seq=0 ...
2 0.000044837 127.0.0.1 → 127.0.0.1 TCP 74 5555 → 55513 [SYN, ACK] Seq=0 Ack=1 ...
3 0.000081713 127.0.0.1 → 127.0.0.1 TCP 66 55513 → 5555 [ACK] Seq=1 Ack=1 ...
4 0.001208524 127.0.0.1 → 127.0.0.1 TLSv1.2 351 Client Hello
5 0.001244352 127.0.0.1 → 127.0.0.1 TCP 66 5555 → 55513 [ACK] Seq=1 Ack=286 ...
6 0.001306859 127.0.0.1 → 127.0.0.1 TCP 66 5555 → 55513 [RST, ACK] Seq=1 Ack=286 ...You can see the standard [SYN] / [SYN,ACK] / [ACK] for connection establishment, then a Client Hello (and
corresponding [ACK]). Then, more or less immediately, an [RST, ACK] as the server drops the connection.
But nothing appears in the server log, so what’s going on?
Ranch
I started digging into the ranch source code, to see if I could figure out what was happening. Ranch is structured like this:
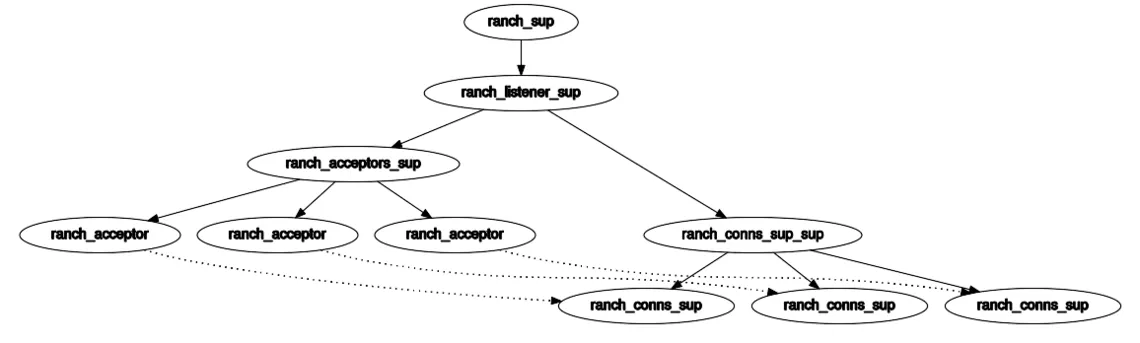
Ranch has a pool of ranch_acceptor processes, which are all listening on the socket and accepting connections. It
defaults to 10 acceptors, but the diagram only shows 3.
When there’s an incoming connection, the operating system (and Erlang) will wake up one of them (arbitrarily) to accept
the socket. The acceptor will ask its associated ranch_conns_sup to start the protocol handler.
The relevant part of the Ranch source code looks like this:
% ranch_acceptor.erl
loop(LSocket, Transport, Logger, ConnsSup, MonitorRef) ->
_ = case Transport:accept(LSocket, infinity) of
{ok, CSocket} ->
case Transport:controlling_process(CSocket, ConnsSup) of
ok ->
%% This call will not return until process has been started
%% AND we are below the maximum number of connections.
ranch_conns_sup:start_protocol(ConnsSup, MonitorRef, CSocket);…etc.
I’m not going to include all of the source code here, but if an error occurs in Transport:accept/2 (which in our case
is ranch_ssl:accept), the error is quietly ignored and the acceptor loops.
At this point, I fired up the Erlang/Elixir debugger, and immediately regretted it, but somehow I managed to figure out
that Transport:controlling_process was being called, which means that Transport:accept was succeeding. So either
Transport:controlling_process was failing or ranch_conns_sup:start_protocol was failing.
So I looked at ranch_conns_sup:start_protocol. It looks like this:
% ranch_conns_sup.erl
start_protocol(SupPid, MonitorRef, Socket) ->
SupPid ! {?MODULE, start_protocol, self(), Socket},
receive
SupPid ->
ok;
{'DOWN', MonitorRef, process, SupPid, Reason} ->
error(Reason)
end.That is: it sends a start_protocol message to the relevant ranch_conns_sup (see the earlier supervision diagram) and
waits for a response. If that fails, the whole thing errors out. That’s uncaught, which means that the ranch_acceptor
would be killed, and I wasn’t seeing that.
If you look at the handling for the start_protocol message, it looks like this:
% ranch_conns_sup.erl
receive
{?MODULE, start_protocol, To, Socket} ->
try Protocol:start_link(Ref, Transport, Opts) of
% ...
catch Class:Reason ->
To ! self(),
% ...log a warning...
Transport:close(Socket),
loop(...)At this point, I should note that I hadn’t actually implemented example_protocol, so Ranch would have been completely
correct to error out.
That is: it would have tried to invoke my non-existent protocol, which would have thrown an error, but that would have
been caught, and Ranch would have logged a warning. I confirmed that that works properly by temporarily switching to
using ranch_tcp rather than ranch_ssl. It logged the warning.
So I now had a solid suspicion that Transport:controlling_process was failing. I checked that by using a custom Ranch
transport, with extra logging. Since I’m actually writing Elixir, it looked a lot like this:
# fake_transport.ex
defmodule FakeTransport do
@behaviour :ranch_transport
@transport :ranch_ssl
defdelegate name(), to: @transport
defdelegate secure(), to: @transport
# and so on, until...
def controlling_process(socket, pid) do
@transport.controlling_process(socket, pid) |> IO.inspect()
end
# etc.
endThat confirmed that controlling_process was returning {:error, :closed}.
The source code for that looks like this:
% ranch_ssl.erl
controlling_process(Socket, Pid) ->
ssl:controlling_process(Socket, Pid).Erlang
And the source code for ssl:controlling_process looks like this:
% ssl.erl
controlling_process(#sslsocket{pid = [Pid|_]}, NewOwner) when is_pid(Pid), is_pid(NewOwner) ->
ssl_connection:new_user(Pid, NewOwner);
% ...another two function clausesSo the first question is: am I sure that this is the correct function clause? It’s a good question, and one I can answer by modifying the custom transport:
# fake_transport.ex
def controlling_process(socket, pid) do
socket |> IO.inspect()
@transport.controlling_process(socket, pid) |> IO.inspect()
endThe socket value looks like this:
{:sslsocket,
{:gen_tcp, #Port<0.7>, :tls_connection,
[option_tracker: #PID<0.216.0>, session_tickets_tracker: :disabled]},
[#PID<0.232.0>, #PID<0.231.0>]}Aside: I wonder if Elixir’s IO.inspect() can be made to understand Erlang records.
The record definition for sslsocket is in ssl_api.hrl and, well…
%% Looks like it does for backwards compatibility reasons
-record(sslsocket, {fd = nil, pid = nil}).Searching in the Erlang/OTP source code, I found the following in dtls_socket.erl:
socket(Pids, Transport, Socket, ConnectionCb) ->
#sslsocket{pid = Pids,
%% "The name "fd" is keept for backwards compatibility
fd = {Transport, Socket, ConnectionCb}}.It looks like the pid field is now a list of pids, and the fd field is, well, some stuff.
Whatever. Our socket has a list of pids in it, so the first clause of the ssl:controlling_process/2 function is the
one we want. It calls ssl_connection:new_user(Pid, NewOwner) using the first pid in the list, which looks like this:
new_user(ConnectionPid, User) ->
call(ConnectionPid, {new_user, User}).…and ssl_connection:call looks like this:
call(FsmPid, Event) ->
try gen_statem:call(FsmPid, Event)
catch
exit:{noproc, _} ->
{error, closed};
exit:{normal, _} ->
{error, closed};
exit:{{shutdown, _},_} ->
{error, closed}
end.…which is extremely promising.
Down the rabbit hole
I need to confess that at this point, I wasted an hour or so looking at how new_user was handled in ssl_connection,
before figuring out that I was looking in the wrong place. That first pid in the list isn’t an ssl_connection.
Allow me to continue down this particular rabbit hole for a while first, though — it’s not without interest.
The first thing to look at is that call, above, converts process death (or an already dead process) to {error, closed}, which is precisely what I’m looking for. So is the process dead?
def controlling_process(socket, pid) do
socket |> IO.inspect()
result = @transport.controlling_process(socket, pid) |> IO.inspect()
# Is the process dead?
{:sslsocket, _, [connection_pid|_]} = socket
:erlang.process_info(connection_pid) |> IO.inspect()
result
endAnswer: no. The process is still alive and kicking. So the {error, closed} has to be coming from the state machine.
It can’t be coming from gen_statem:call itself because why would gen_statem know anything about closed sockets? So
I ignored that possibility.
Also remember I was still looking at the wrong code at this point. If I’d been paying closer attention at this point, I’d have figured that out sooner. I’ll pick that thread up later.
I spent some time digging in the ssl_connection source code, looking at how it handled new_user, and couldn’t figure
out exactly what was happening. I got to this piece of code:
% ssl_connection.erl
handle_call({new_user, User}, From, StateName,
State = #state{connection_env = #connection_env{user_application = {OldMon, _}} = CEnv}, _) ->
NewMon = erlang:monitor(process, User),
erlang:demonitor(OldMon, [flush]),
{next_state, StateName, State#state{connection_env = CEnv#connection_env{user_application = {NewMon, User}}},
[{reply, From, ok}]};…but that doesn’t return the error, and doesn’t seem to have any obvious way to fail.
Maybe the state machine’s not in the state I think it is? We can query a gen_statem for its state by calling
sys:get_state(Pid), so I did that:
# fake_transport.ex
def controlling_process(socket, pid) do
{:sslsocket, _, [connection_pid|_]} = socket
# What state is the gen_statem in?
:sys.get_state(connection_pid) |> IO.inspect()
@transport.controlling_process(socket, pid) |> IO.inspect()
endIt throws an error with a whole pile of stuff in it. What? How? More digging.
sys:get_state(Pid) looks like this:
get_state(Name) ->
case send_system_msg(Name, get_state) of
{error, Reason} -> error(Reason);
State -> State
end.Ah. gen_statem returns {StateName, StateData}, but our state machine is apparently in the error state, so it
returns {error, Data}, which sys:get_state interprets, well, as an error, and converts it to an exception. Whoops.
dbg to the rescue?
At this point, I broke out Erlang’s dbg module:
:dbg.start()
:dbg.tracer(:process, {fn m, _ -> IO.inspect(m) end, nil})
:dbg.tpl(:ssl, :controlling_process, :_, [{:_, [], [{:return_trace}]}])
:dbg.tpl(:ssl_connection, :_, :_, [{:_, [], [{:return_trace}]}])
:dbg.p(:all, :c)This:
- starts the text-mode debugger
- registers a function as the tracer
- enables call traces for the
ssl:controlling_processfunction and for every function in thessl_connectionmodule - and logs the return values.
- turns on call tracing for all processes.
The trace output from that was noisy, but I spotted an interesting thing in it: there was a call to
ssl_connection:ssl_config immediately after the call to ssl_connection:new_user and its call to
ssl_connection:call.
But I had already looked at the code that handles new_user:
% ssl_connection.erl
handle_call({new_user, User}, From, StateName,
State = #state{connection_env = #connection_env{user_application = {OldMon, _}} = CEnv}, _) ->
NewMon = erlang:monitor(process, User),
erlang:demonitor(OldMon, [flush]),
{next_state, StateName, State#state{connection_env = CEnv#connection_env{user_application = {NewMon, User}}},
[{reply, From, ok}]};…and that doesn’t call ssl_connection:ssl_config. So who the hell does?
It’s called from a few places inside ssl_connection, none of which looked particularly relevant, and from
tls_connection:init/1, which might be relevant (narrator: extremely relevant, as it turns out).
ssl_connection:ssl_config calls ssl_config:init, so I added some more call tracing:
:dbg.start()
:dbg.tracer(:process, {fn m, _ -> IO.inspect(m) end, nil})
:dbg.tpl(:ssl, :controlling_process, :_, [{:_, [], [{:return_trace}]}])
:dbg.tpl(:ssl_connection, :_, :_, [{:_, [], [{:return_trace}]}])
:dbg.tpl(:ssl_config, :_, :_, [{:_, [], [{:return_trace}]}])
:dbg.p(:all, :c)Looking in the trace, I didn’t see a return from ssl_config:init, but I did see this instead:
{:trace, #PID<0.235.0> :call,
{:ssl_config, :file_error,
[
"server.crt",
{:certfile, {:badmatch, {:error, {:badmatch, {:error, :enoent}}}}}
]}}So the last thing to happen was that something called ssl_config:file_error. Now, I already knew that "server.crt"
wasn’t a valid certificate file, but what’s going on in file_error?
It looks like this:
file_error(File, Throw) ->
case Throw of
{Opt,{badmatch, {error, {badmatch, Error}}}} ->
throw({options, {Opt, binary_to_list(File), Error}});
{Opt, {badmatch, Error}} ->
throw({options, {Opt, binary_to_list(File), Error}});
_ ->
throw(Throw)
end.It throws the error, which means that some code somewhere is either catching it, or dying. I know that nothing’s dying, because I checked for that earlier, so something’s catching it and… then what?
Looking for ssl_config in the ssl_connection.erl file (remember: I’m still on a wild goose chase at this point)
leads to this section of code:
init({call, From}, {start, {Opts, EmOpts}, Timeout}, #state{...} = State0) ->
try
SslOpts = ssl:handle_options(Opts, Role, OrigSSLOptions),
State = ssl_config(SslOpts, Role, State0),
% ...
catch throw:Error ->
{stop_and_reply, {shutdown, normal}, {reply, From, {error, Error}}, State0}
end;…which looks plausible — we’re probably in the init state (at this point I forgot that I already knew that we were
in the error state). But {stop_and_reply, {shutdown, normal}, ...} causes the process to die, and we know that’s not
happening (because erlang:process_info succeeds).
Sniffing around the right tree
Yes, I’ve mixed three metaphors (so far).
I mentioned earlier that tls_connection:init also calls ssl_connection:ssl_config. It looks like this:
init([...]) ->
% ...
try
State = ssl_connection:ssl_config(State0#state.ssl_options, Role, State0),
initialize_tls_sender(State),
gen_statem:enter_loop(?MODULE, [], init, State)
catch throw:Error ->
EState = State0#state{protocol_specific = Map#{error => Error}},
gen_statem:enter_loop(?MODULE, [], error, EState)
end.Interesting. If ssl_connection:ssl_config throws an error (and we know that it does), we call gen_statem:enter_loop
with error as our initial state.
So, who calls tls_connection:init/1? That’s an easy question: tls_connection:start_link/1 causes it to be called.
Who calls that? That’s a hard question.
It’s at this point that I spent some time failing to persuade dbg to give me caller information…
Searching for tls_connection:start_link doesn’t return any results — it’s not called explicitly.
Searching for tls_connection in ssl.erl reveals that it’s commonly found in the connection_cb field in #config{}.
I then noticed the tls_connection_sup module, which sounds like it might be supervising tls_connection processes.
Some more digging, and I’d got this:
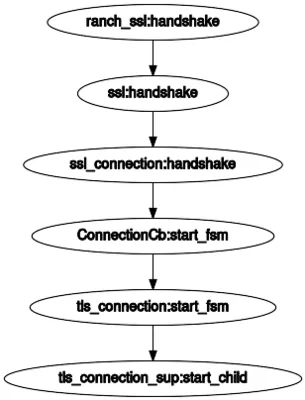
So I’d got a tls_connection process, which was already in the error state. At this point I was starting to suspect
that I wasn’t looking at an ssl_connection process after all.
Then I realised that ssl:controlling_process looks like this:
controlling_process(#sslsocket{pid = [Pid|_]}, NewOwner) when is_pid(Pid), is_pid(NewOwner) ->
ssl_connection:new_user(Pid, NewOwner);That Pid could be a tls_connection. How do we check that?
You might remember this code from earlier:
# Is the process dead?
{:sslsocket, _, [connection_pid|_]} = socket
:erlang.process_info(connection_pid) |> IO.inspect()Taking a closer look at that, we find the following:
[
# ...
dictionary: [
"$initial_call": {:tls_connection, :init, 1},
"$ancestors": [:tls_connection_sup, :tls_sup, :ssl_connection_sup, :ssl_sup, #PID<0.125.0>],
# ...
],
# ...
]Which confirms that we’re looking at a tls_connection, and shows its supervisor tree. If I’d been paying more
attention earlier, I’d have spotted that and would have saved a bunch of time.
Barking up the right tree
So, what happens if someone calls tls_connection with new_user while it’s in the error state? It calls this:
error({call, _} = Call, Msg, State) ->
gen_handshake(?FUNCTION_NAME, Call, Msg, State);…which calls gen_handshake(error, ...), which calls ssl_connection:error, as follows:
gen_handshake(StateName, Type, Event, State) ->
try ssl_connection:StateName(Type, Event, State, ?MODULE) of
Result ->
Result
% ...The use of ?FUNCTION_NAME and StateName doesn’t make this easy to follow, incidentally.
ssl_connection:error looks like this:
error({call, From}, _Msg, State, _Connection) ->
{next_state, ?FUNCTION_NAME, State, [{reply, From, {error, closed}}]}.…and that’s our {error, closed}.
Now what?
So we’ve figured out the problem: make sure that you specify certfile and keyfile options that point to valid files.
To detect a misconfiguration when our service starts, we can do something like this:
defmodule MySslTransport do
# ...
def listen(opts) do
Keyword.get(opts, :certfile) |> File.read!() |> validate_is_pem!()
Keyword.get(opts, :keyfile) |> File.read!() |> validate_is_pem!()
@transport.listen(opts)
end…which is (more-or-less) what’s going to end up in our production server at some point.