k3s on Raspberry Pi: Docker push fails
Pushing a simple node.js-based image to my private docker registry failed.
I pushed a simple node.js server to my private docker registry, as follows:
docker build -t node-server .
docker tag node-server 10.43.236.176:5000/node-server
docker push 10.43.236.176:5000/node-serverIt successfully pushed a number of layers, and then got stuck retrying the others:
$ docker push 10.43.236.176:5000/node-server
Using default tag: latest
The push refers to repository [10.43.236.176:5000/node-server]
014e5dcedfe8: Layer already exists
bad58bc1a935: Layer already exists
0b6d7299e601: Layer already exists
29de97afcd26: Retrying in 4 seconds
70bf7068bc9b: Layer already exists
df0a11e357d6: Retrying in 5 seconds
43d8f1a52a9d: Retrying in 5 seconds
ad6e20c8404a: Retrying in 5 seconds
5379afcf1a28: Retrying in 5 secondsWhat’s in the logs?
$ kubectl --namespace docker-registry get pods
NAME READY STATUS RESTARTS AGE
docker-registry-887c57b6b-gr6c7 1/1 Running 0 19h
$ kubectl --namespace docker-registry logs docker-registry-887c57b6b-gr6c7
... lots of logging ...The logging is really hard to read, but somewhere in it, I can see the following:
10.42.0.0 - - [18/Dec/2021:16:10:19 +0000] "POST /v2/node-server/blobs/uploads/ HTTP/1.1" 500 247 "" "<user-agent>" ...
err.detail="filesystem: mkdir /var/lib/registry/docker/registry/v2/repositories/node-server/_uploads/74b0a3e2-5898-450b-aec0-fcddf608e18d: read-only file system"Read-only file system?
The filesystem’s read-only? It was writeable a moment ago. Huh?
What I suspect has happened here is that my iSCSI setup has got itself in a muddle. We should check a few things.
First: is the file system, as seen by the container, read-only?
$ kubectl --namespace docker-registry exec --stdin --tty docker-registry-887c57b6b-gr6c7 -- /bin/sh
# cd /var/lib/registry/docker/registry/v2/repositories
# ls
hello-world node-serverWell, we’ve obviously managed to upload some of the image. Is the filesystem still read-only?
# touch foo
touch: foo: Read-only file system
# mount | grep /var/lib/registry
/dev/sdb on /var/lib/registry type ext4 (ro,relatime)Yes. OK. So it’s not lying. How did it get into this state? Running dmesg -T on the relevant node is, well, both pretty (all those colours!) and not pretty (all that stack trace):
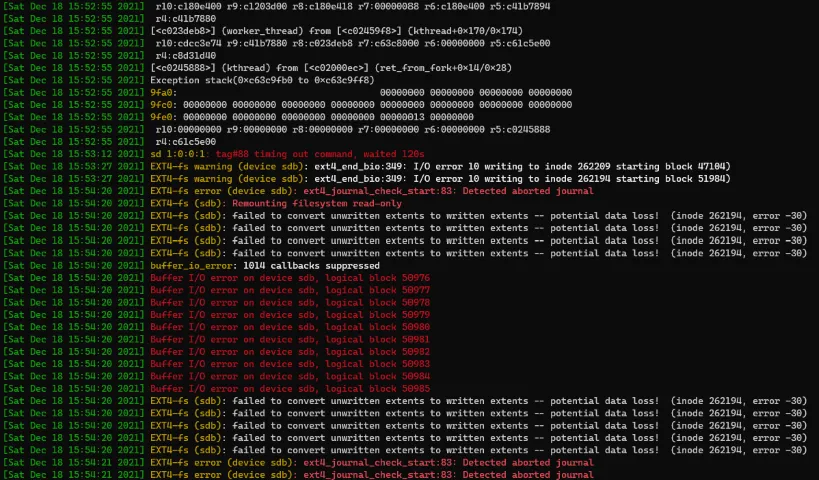
This bit:
[861609.960890] EXT4-fs error (device sdb): ext4_journal_check_start:83: Detected aborted journal
[861609.960917] EXT4-fs (sdb): Remounting filesystem read-onlyThis is not funny. Filesystems only do this when they’re extremely distressed.
I restarted the pod on another node, which remounted the filesystem read-write and tried again.
Don’t try this at home. You should recover the volume and run fsck first. But, hey, test rig. #yolo.
When retrying, that also failed after a while:
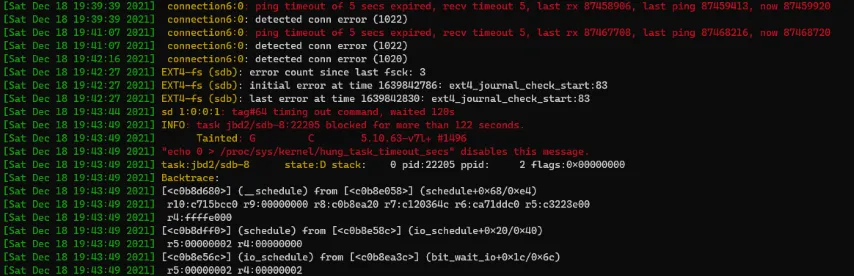
To be honest, I think that my DS211 might be a bit underpowered to act as an iSCSI target (at least without some tweaks to the client configuration, anyway). Or maybe it’s just a bad disk — I found it in my parts bin, and it’s several years old. It also reports power-on time of ~30K hours. I should have done some more soak-testing first.
Conclusion
I’ll give up on that for the time-being.
Let’s go back to dynamically-provisioned storage, even if it does make the pod have node affinity. We can take another look at alternatives later.